Author:baiyucraft
BLog: baiyucraft’s Home
IDE:PyCharm
一、BeatifulSoup4的安装及简略
1.安装BeautifulSoup4
BeautifulSoup4也是Python的第三方库,所以需要安装,同样也有两种方法
1)使用命令行通过pip安装:
1
| $ pip install beautifulsoup4
|
2)使用Pycharm来安装,同样是之前的方法,这里不多说
2.引用BeautifulSouop4
主要用的是BeautifulSoup类
1
| from bs4 import BeautifulSoup
|
或者也可以直接导入
3.使用BeautifulSoup4
要使用这个库,需要对html语言有点了解,需要了解标签的概念,如果有不懂的可以去看我的html教程
具体详细使用方法可以看文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
BeautifulSoup4的使用是对于html文档的:
1
2
3
4
|
bs = BeautifulSoup.(rs.text)
|
在了解了html标签的特性后,一般才用两种方式来遍历查找自己想要的内容
1) 采取find_all()方法
1
2
3
4
5
6
|
bs.find_all('p')
bs.find_all('p', class_ = "article")
|
2)用CSS选择器搜索
1
2
3
4
5
6
7
|
bs.select('p')
bs.select('.article')
bs.select('a[href]')
|
有了这些最最基础的基础,我们就可以爬取我们小说网站的整本小说了
二、爬取小说网站的过程
这里爬取的是顶点小说网,这是爬取书的网址:http://www.dingdiansk.com/book/5.html
打开网址,我们知道,每个章节目录对应的是一个该章节的网址:

我们点击第一章,右键审查元素,可以发现我们的链接是在<a>标签中的:
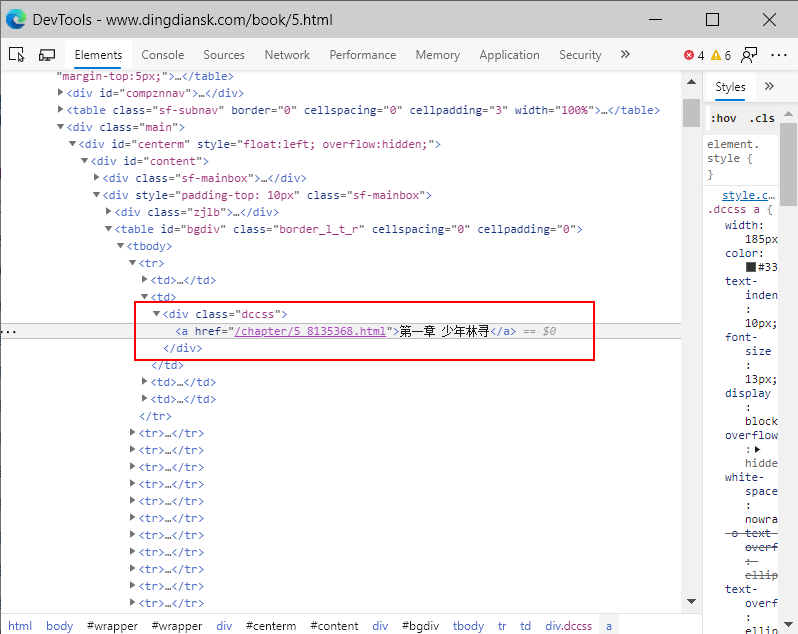
但是,一个html网页中有好多<a>标签,这个没有什么标识性,我们将目标瞄准在这个<a>标签的父级标签,class = "dccss"的<div>标签,代码如下:
1
2
3
4
5
6
7
8
|
chaper_d = bs.find_all(class_ = "dccss")
chaper_a = []
for chaper_d in chaper_d_list:
chaper_a.append(chaper_d.find_all('a'))
chaper_a = bs.select('.dccss > a')
|
两种方法效果一样,都能得到我们的章节列表的<a>标签:

我们对遍历所有的<a>标签,取出其中的章节链接和章节名:
1
2
3
4
| chaper_l = []
for chaper in chaper_a:
chaper_l.append([chaper["href"],chaper.string])
|
接下来我们需要对一个章节中的文本内容进行爬取,我们分析第一章的html内容:
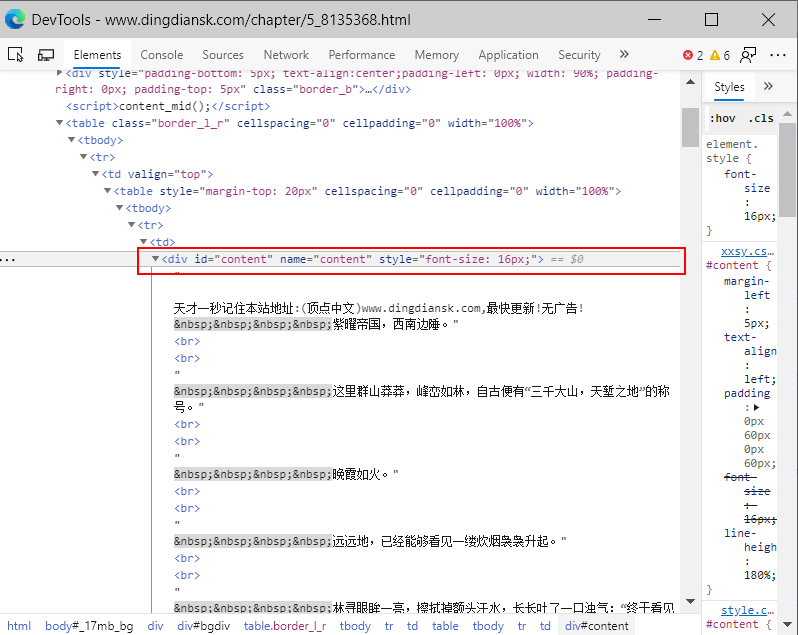
发现所有的文本内容都在id = “content”的<div>标签内,我们需要获取<div>标签中所有的文本内容,代码如下:
1
2
3
4
5
|
cont = bs.select('#content')
chaper_text = cont[0].get_text()
|
这样我们第一章的文本内容就全部被获取了,是不是so easy!
下一步就是完善代码,写入文件以及添加交互,最终封装成类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
import requests
from bs4 import BeautifulSoup50
import os
class Novel():
def __init__(self):
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
}
self.url = "http://www.dingdiansk.com"
self.novel_path = 'novel'
self.novel_id = input("请输入小说的序号:")
self.book_url = self.url + "/book/" + self.novel_id + ".html"
def get_html(self, url):
rs = requests.get(url, headers=self.header)
rs.encoding = "utf-8"
bs = BeautifulSoup(rs.text,"html5lib")
return bs
def get_chaper(self):
chaper_a = self.get_html(self.book_url).select(".dccss > a")
self.chaper_l = []
for chaper in chaper_a:
self.chaper_l.append([chaper["href"],chaper.string])
def get_title(self):
self.novel_title = self.get_html(self.book_url).select('meta[property="og:novel:book_name"]')[0]["content"]
print("正在下载小说:《"+self.novel_title+"》...")
def downlaodChaper(self):
if not os.path.exists(self.novel_path):
os.mkdir(self.novel_path)
with open(self.novel_path + '/' + self.novel_title + ".txt", 'w', encoding="utf-8") as f:
for chaper in self.chaper_l:
cont = self.get_html(self.url+chaper[0]).select("#content")
print("正在下载 "+chaper[1])
chaper_text = cont[0].get_text()
f.write(chaper[1]+'\n')
f.write(chaper_text+'\n')
f.close()
if __name__ == "__main__":
n = Novel()
n.get_chaper()
n.get_title()
n.downlaodChaper()
|
这样我们就可以自己通过爬虫来下载小说了!