(梳理中)YOLO 总结:从 YOLO 看目标检测 Object Detection
Author:baiyucraft
BLog: baiyucraft’s Home
YOLO系列论文:
- You Only Look Once: Unified, Real-Time Object Detection
- YOLO9000: Better, Faster, Stronger
- YOLOv3: An Incremental Improvement
- YOLOv4: Optimal Speed and Accuracy of Object Detection
- YOLOv5: (no paper)
一、YOLO
YOLO系列在目标检测中的有着不可替代的地位,正如YOLO系列第二篇标题中所说,YOLO 实现了Better、Faster、Stronger。
YOLOv1 - YOLOv3 可以说是 YOLO 的第一个阶段,也是 Joseph Redmon 作为一作所写的 YOLO 三篇论文。
YOLOv4 可以算是YOLO的第二个阶段,虽然很遗憾的是 Joseph Redmon 退出了CV界。YOLOv4 论文像是目标检测的集大成,对比了诸多模块,并做了大量的对比。所以从 YOLOv4 论文可以看出 Detection 方向,研究者们所做的一些有效的研究。
YOLOv5 并不能完全算作 YOLO 系列,毕竟不是 YOLO 那一批人做的,也没有发表论文,但是不得不否认,YOLOv5的效果确实很好,并且目前还在随着研究更新着已经到了6.0的版本。
本篇博客从主要从YOLOv4的论文和YOLOv5源码出发,从 YOLO 中来看 Detection 。
二、Related work
1. models
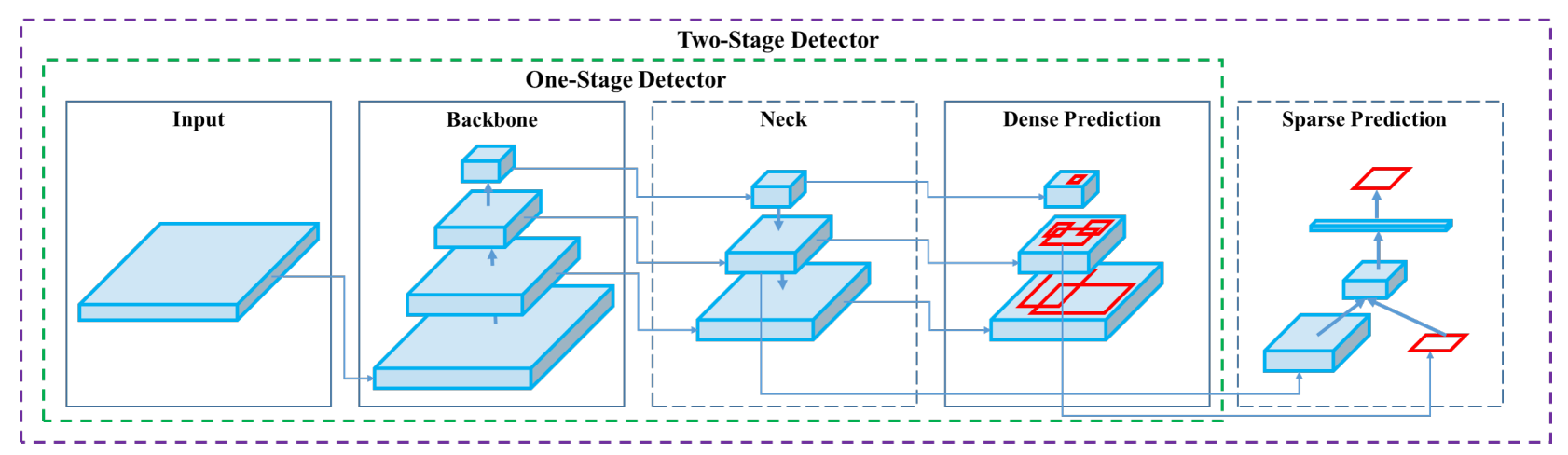
众所周知,目标检测分为 one-stage 和 two-stage 的两大类不同算法,主要区别是针对已经经过特征提取的特征图,预测 box 和 classs 。
经典的 two-stage 算法如 R-CNN 系列,根据特征图生成的一些宽高比不同的框,第一个阶段先预测这些框中是否有 object ,第二个阶段再针对有 object 的框预测其类别。
经典的 one-stage 算法就如 YOLO 系列,根据特征图生成的一些宽高比不同的框,在一个阶段内预测框中是否有目标以及框中的类别。
下面将从如图所示的 Detector 结构图中,逐个介绍在一系列研究中所提出的算法。
(1) Input:
针对目标检测这个任务,输入的当然是图片,当然这些图片是已经进行预处理过后的图片,所以针对图片的预处理的算法,有如下:
Data Augmentation
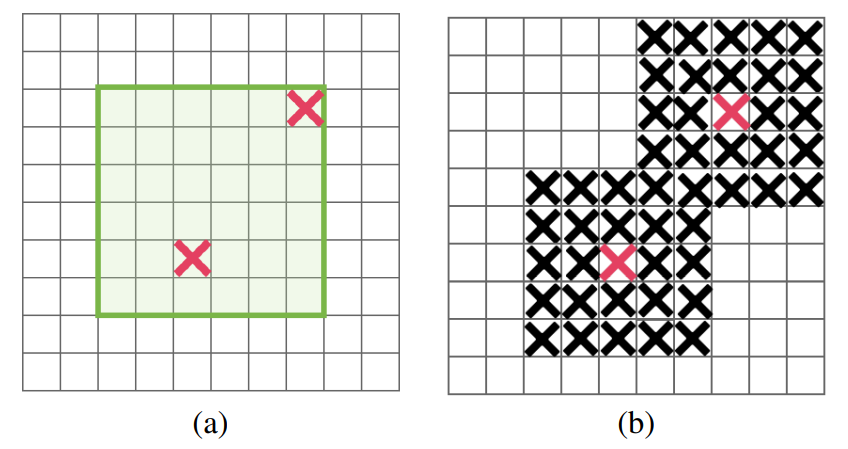
- Random Erasing: 随机初始化面积 和宽高比 , , ,初始化 和 , 并将 的值随机取 。

- CutOut: 随机选取中心点,覆盖一个固定大小的方形zero-mask(通过网格搜索得到)。

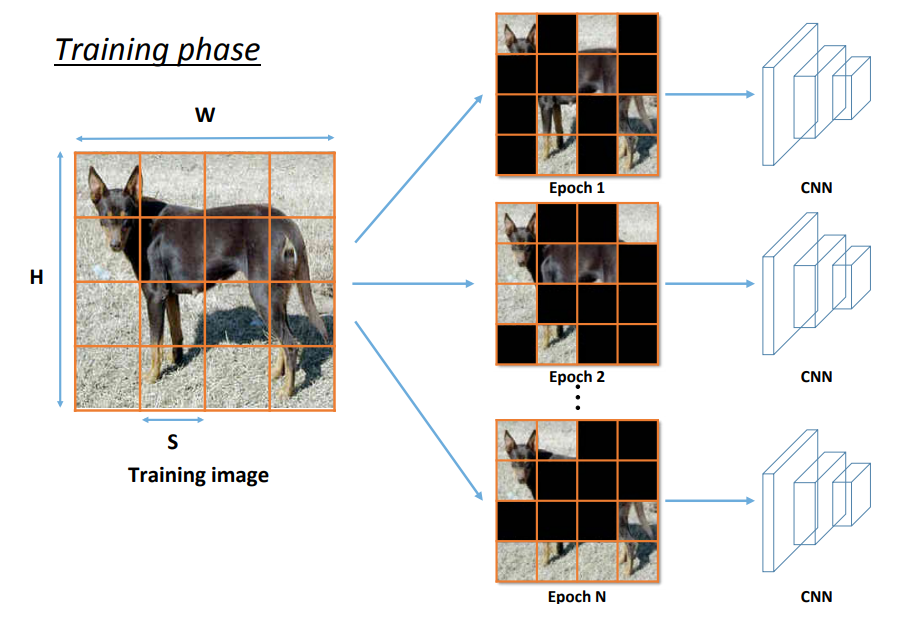
- Hide-and-Seek: 将图片切分为 S×S 个区域,每个区域 0.5 的概率隐藏,用均值填充。
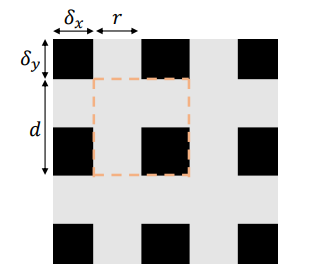
- GridMask: 生成 , , , 来确定mask区域。
- DropBlock: 针对feature maps的正则化,选取固定的区域 block_size , ,依照概率 drop 掉,()
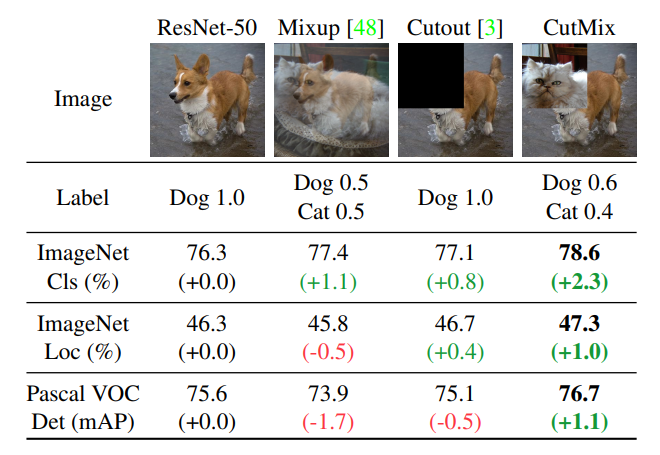
- Mosic
Image
Patches
Image Pyramid
(2) Backbones:
在一个目标检测任务中,Backbones 也就是主干网络主要用于特征提取,一般就是只要是用于图像分类任务的网络,都能用来作为一个 Detector 的 Backbones。一般的操作是将一个分类网络取到 AdaptiveAvgPool 的部分,然后针对 Backbones 生成的不同尺度的初始特征图,做 Detector 的其他操作。由于 YOLO 系列是完全运用 CNN 的方式来进行预测的,所以本篇博客主要关注运用 CNN 的 Backbones 的,不关注运用 Transformer 的如 ViT 的 Backbones。
- VGG16
- ResNet50:
- ResNeXt50:
- DenseNet:
- SqueezeNet
- MobileNet、MobileNetV2、MnasNet、MobileNetV3
- ShuffleNet、ShuffleNetV2
- SpineNet
- EfficientNet-B0/B7
- CSPResNeXt50/CSPDarknet53
- DetNet
- DetNAS
- Hit-Detector
(3) Neck
Additional blocks:
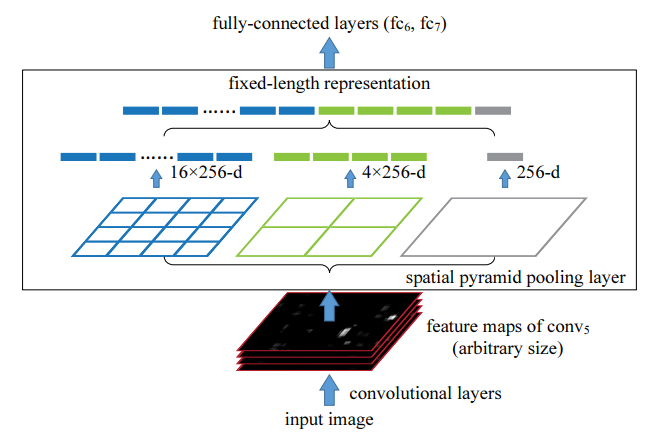
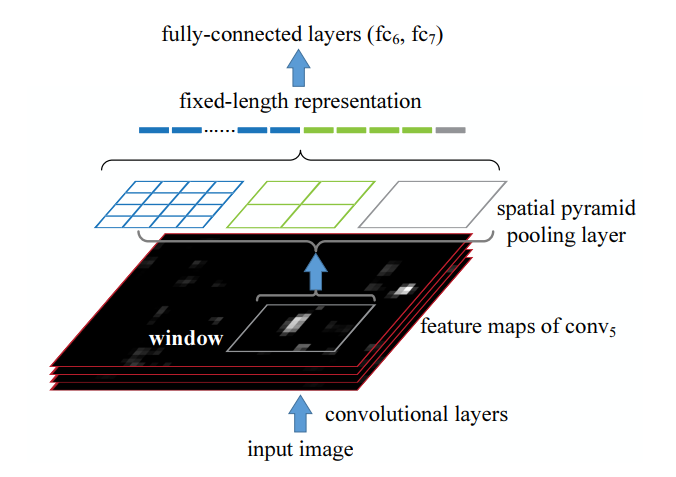
- SPP: 在图像分类任务中,卷积生成的特征图后,通过不同的池化生成(4×4)、(2×2)、(1×1)的图像,并都拉长成向量。目标检测中同理。
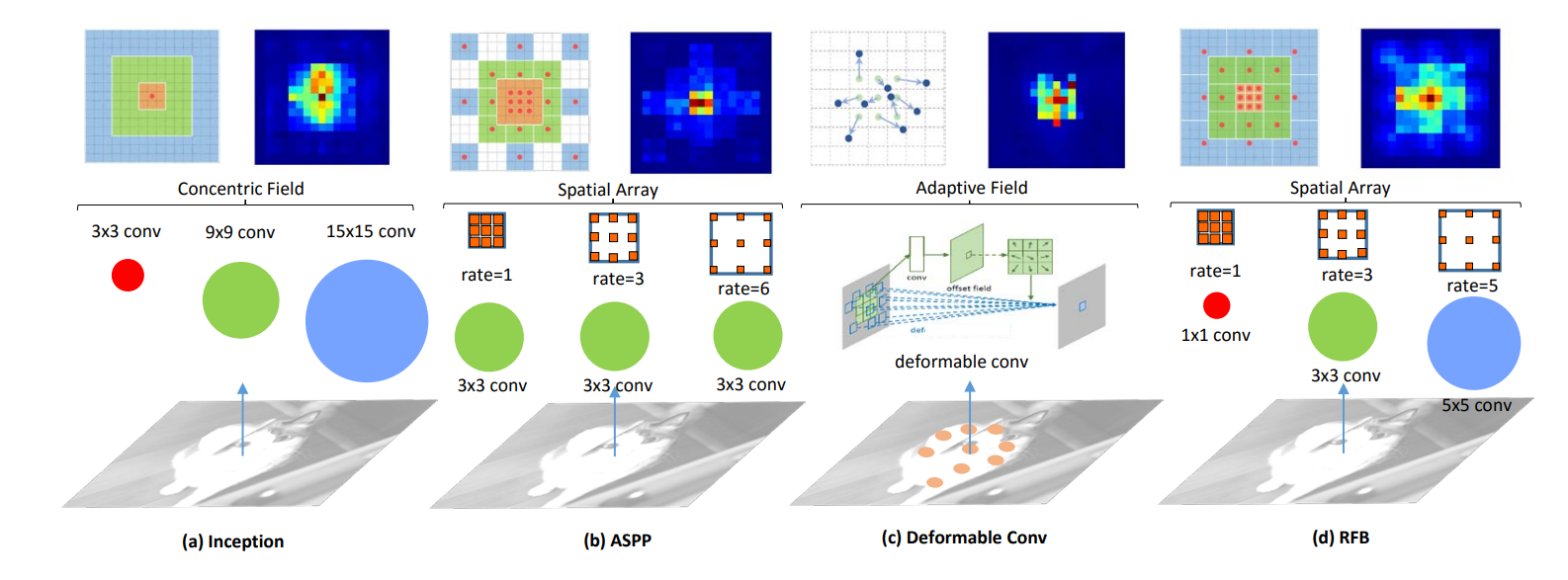
- ASPP: 通过四个不同的空洞卷积,生成不同的特征图,然后cat,达到融合不同感受野信息的目的。
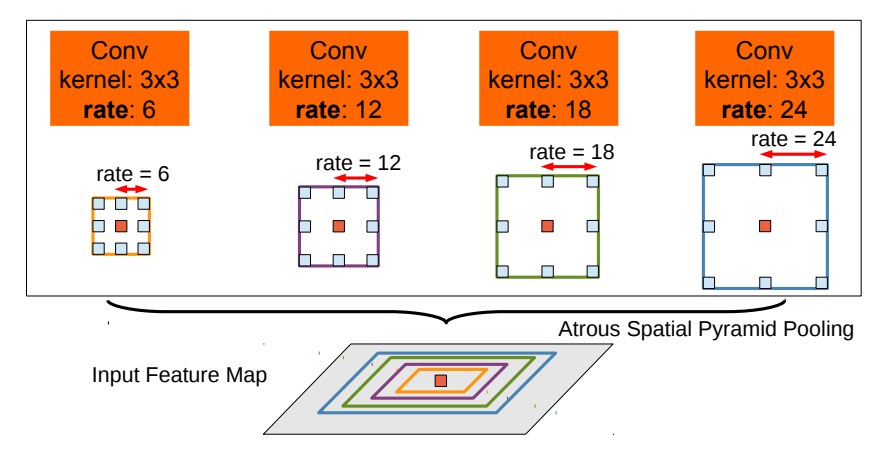
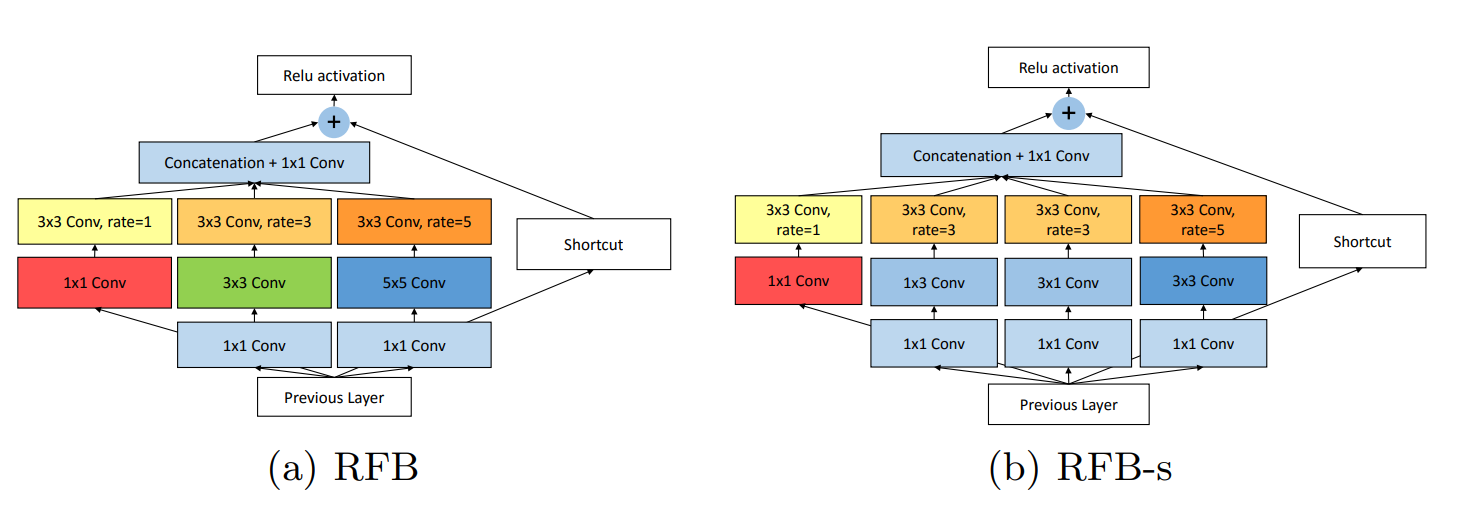
- RFB: 将多路空洞卷积修改为1、3、5的空洞率,并应用于SSD。
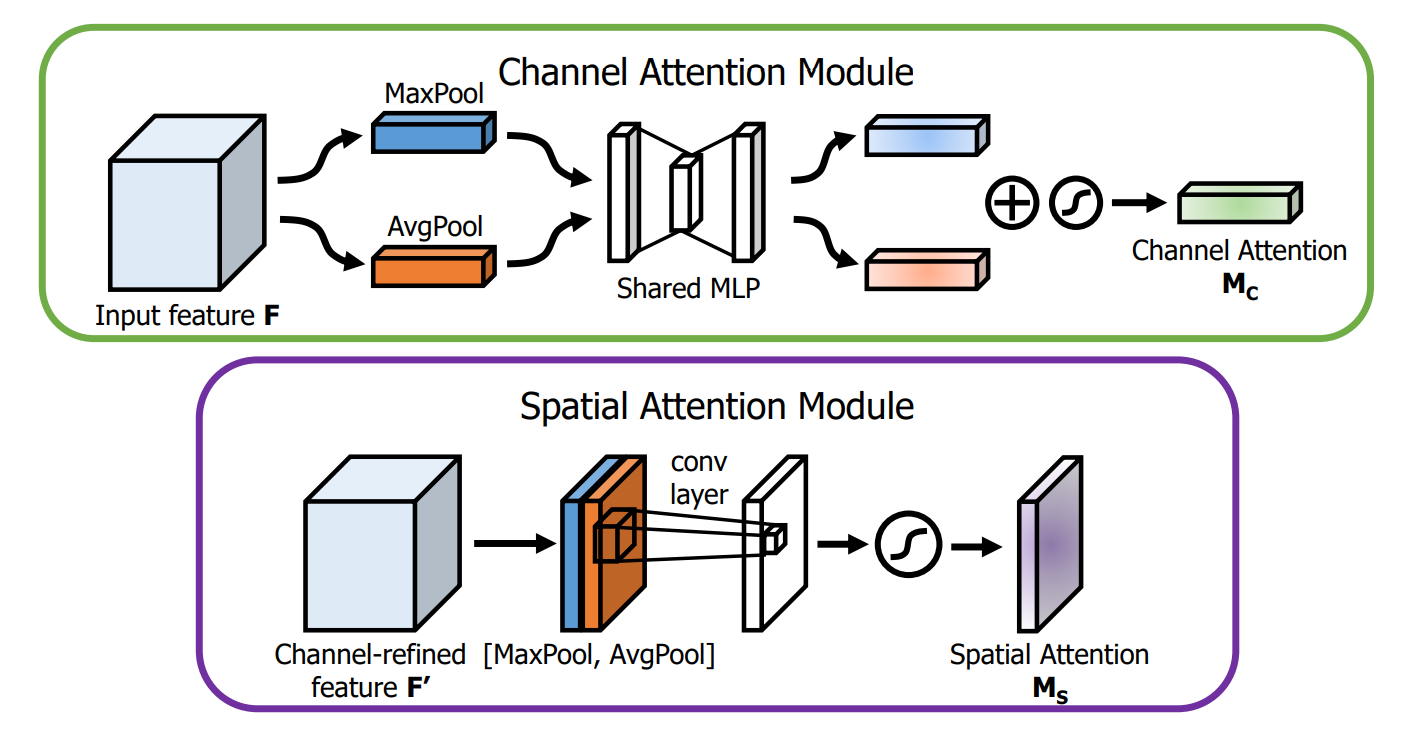
- CBAM(SAM): 注意力机制的模块,分为通道注意力机制(CAM)和空间注意力机制(SAM),分别如图所示:
Path-aggregation blocks:
- FPN: 特征金字塔的方式融合特征图
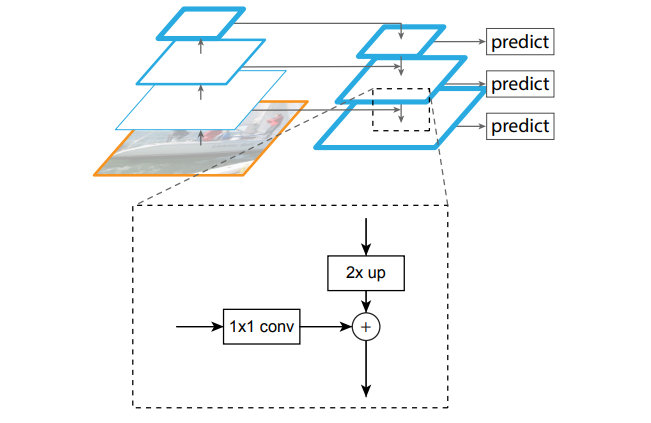
- PAN: 在FPN的基础上增加了自底向定的特征图融合(通过 3×3 步长为2的卷积),并增加了自适应特征池化(全连接分支融合算是分割那边的)
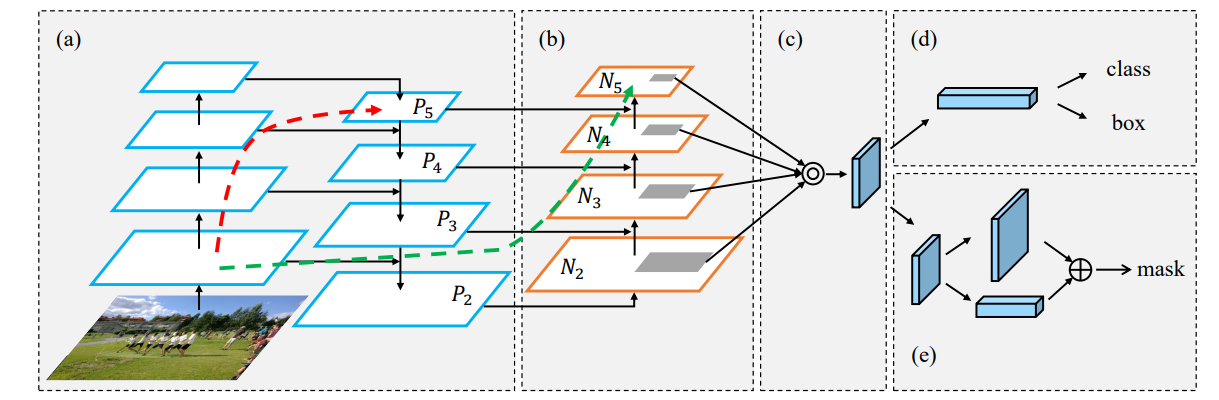
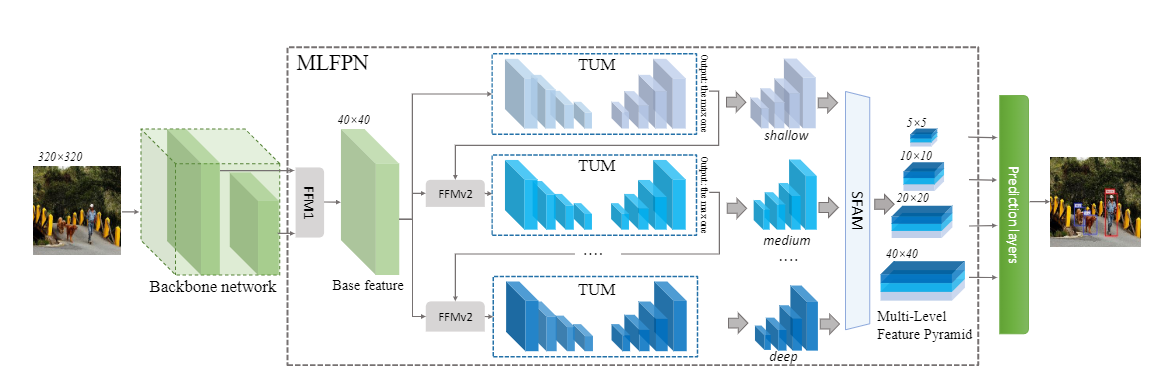
- SFAM(MLFPN): 将主干网络生成的不同特征图先通过FFMv1融合成基础特征,然后通过FFMv2和TUM得到不同级别的特征,最后针对得到的所有特征,通过SFAM进行融合,得到不同尺度的用于检测的特征图
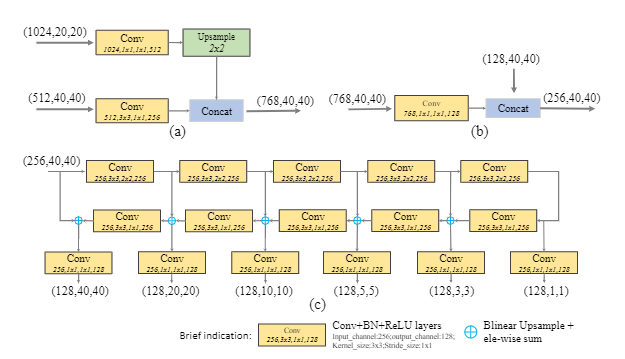
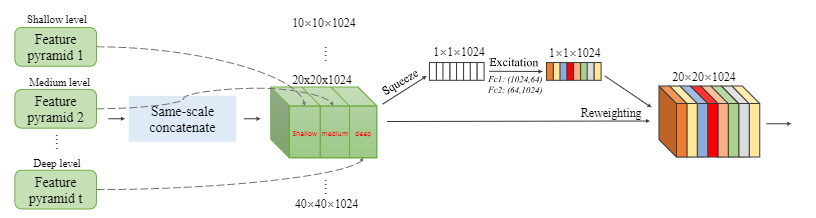
- NAS-FPN: 通过神经网络搜索进行多次的特征图融合(NAS消耗大量算力)
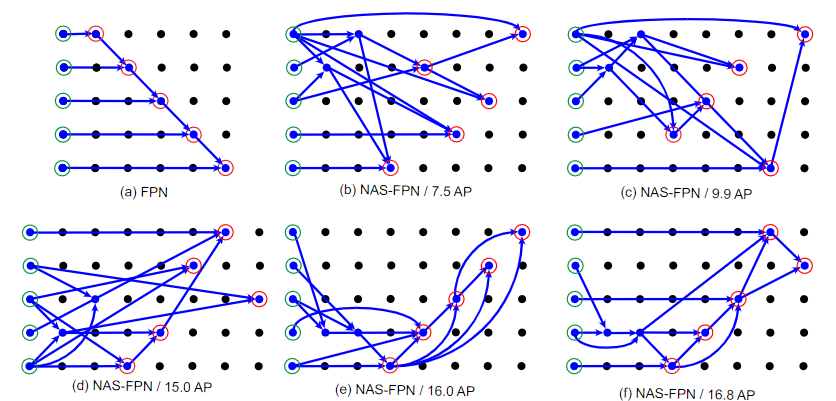
- BiFPN: 加权双向特征金字塔,改进了PANet的连接方式,并在不同分辨率的特征图之间进行加权融合(三种不同的加权融合方式)
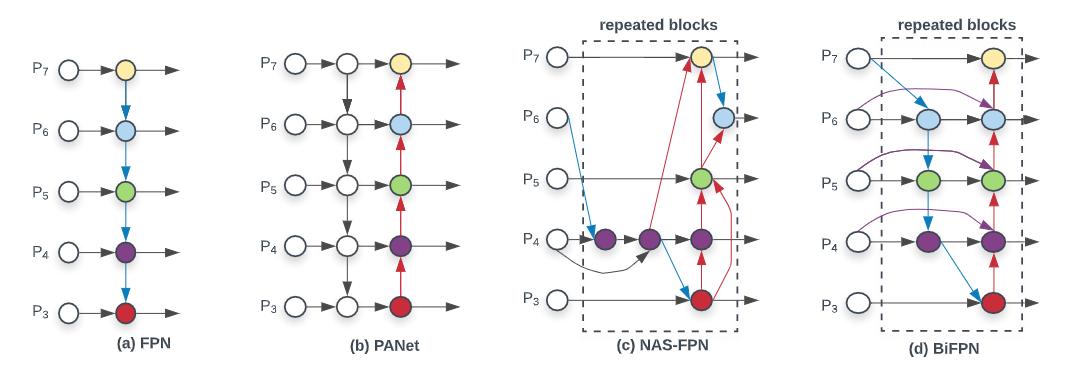
- ASFF: 自适应空间特征融合,将不同分辨率的特征图按不同权重进行融合,分别生成不同大小的特征图自适应学习权重
(4) Heads
Dense Prediction (one-stage):
anchor based
- SSD: SSD中提取的锚框生成方法
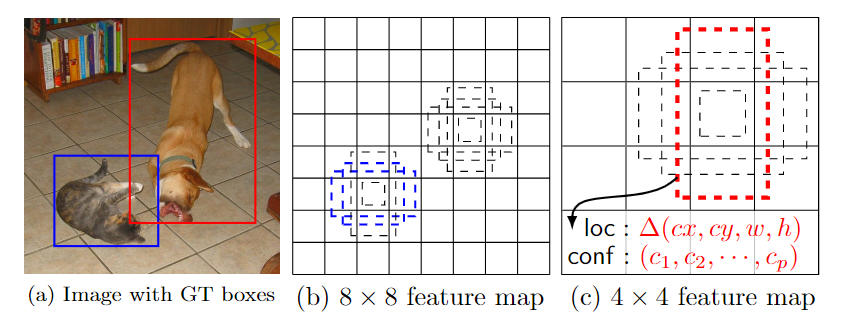
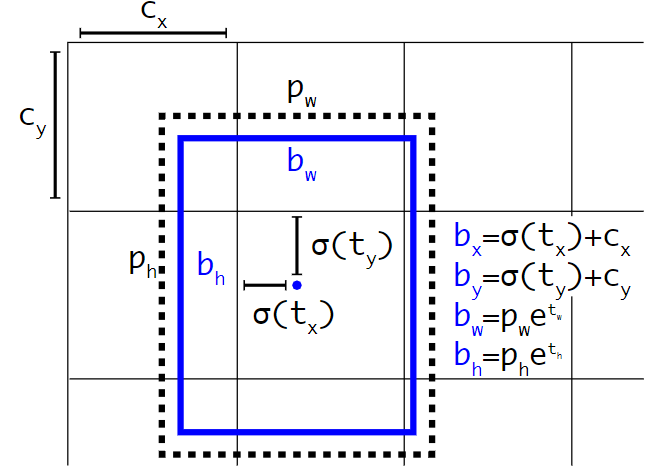
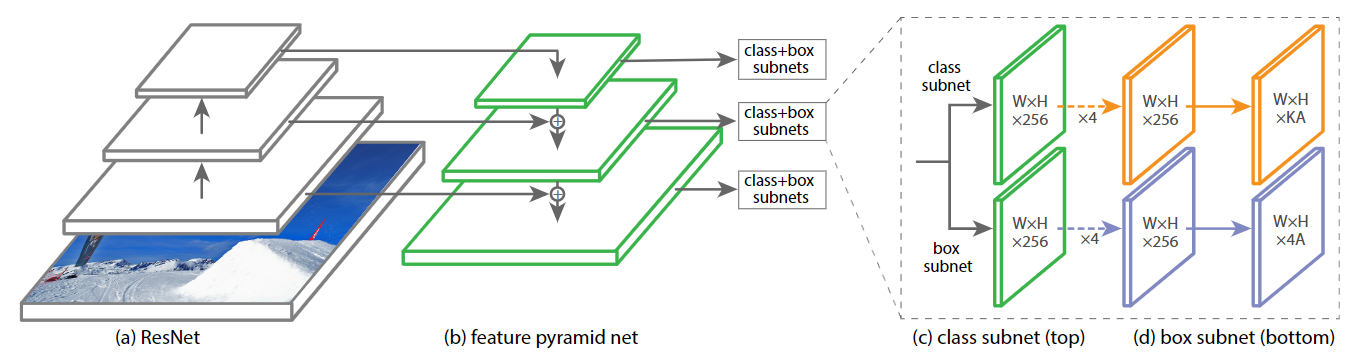
- RetinaNet(Focal Loss): RetinaNet中锚框生成方法
anchor free
- CornerNet、CornerNet-Lite: 通过corner pooling确定目标位置
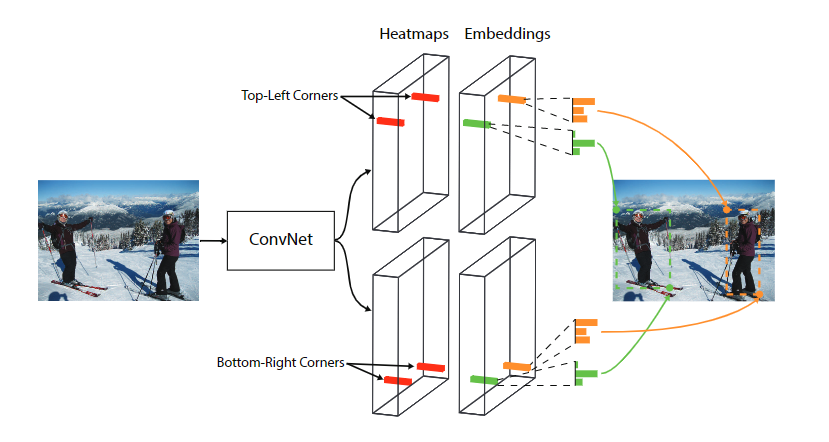
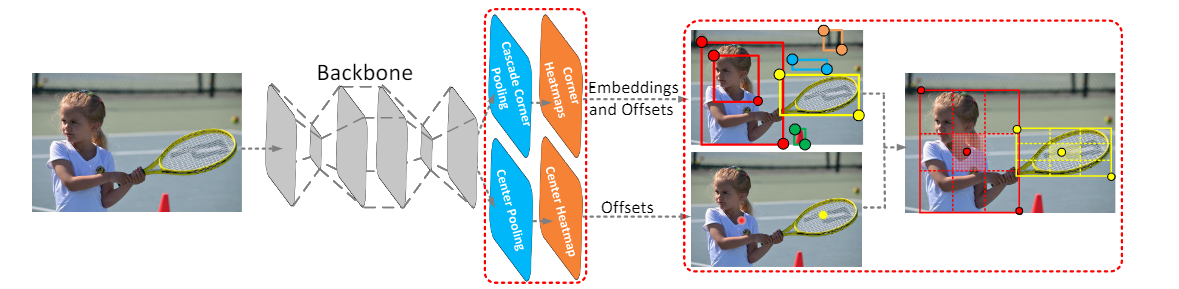
- CenterNet: 在CornerNet的两个角点的判断的基础上,增加中心点的判断增加生成框的置信度
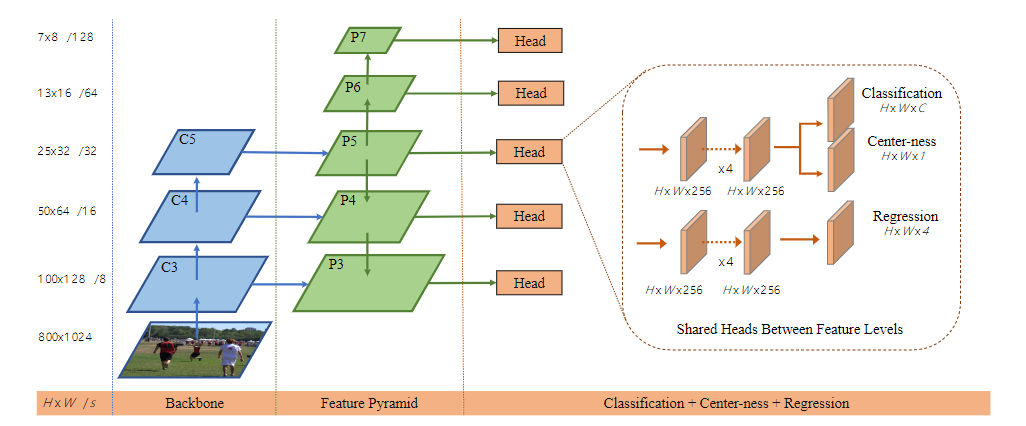
- FCOS: 从FCN受到启发,将特征图中的每个位置对应原图的边框都进行回归,并增加中心度提高性能
Sparse Prediction (two-stage):
anchor based
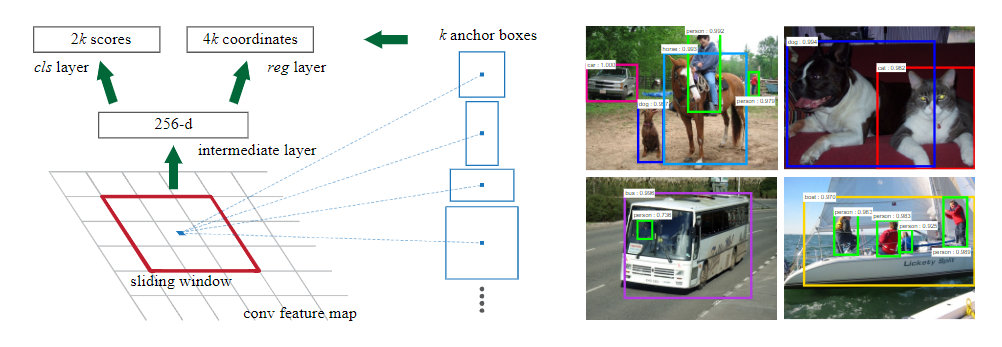
- Faster R-CNN: Faster-RCNN提出的区域建议网络,针对的锚框生成
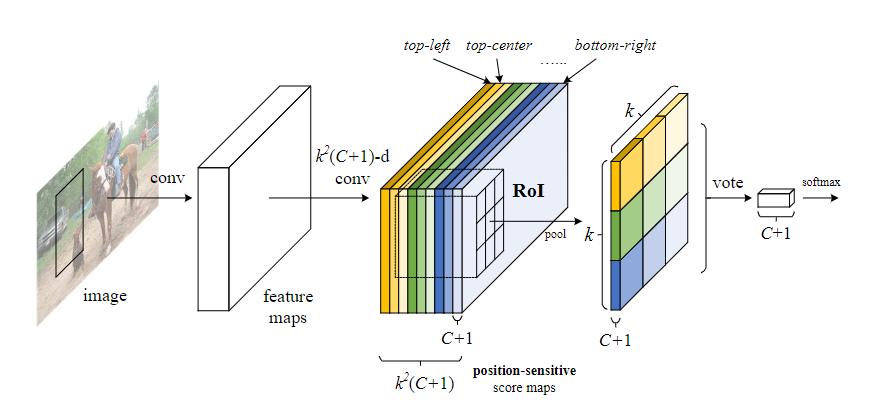
- Mask R-CNN: mask分支
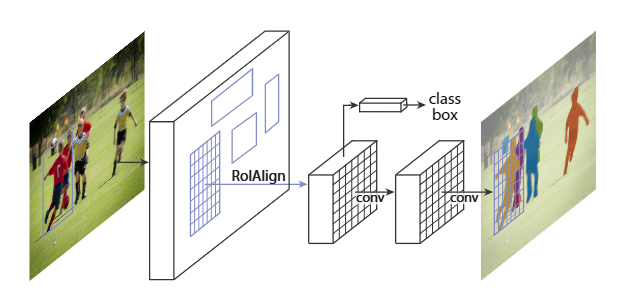
anchor free
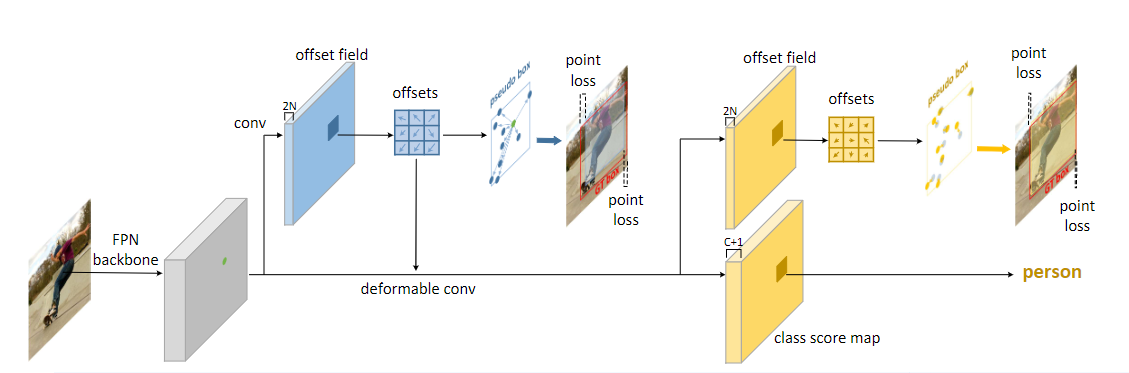
- RepPoints: 先得到点,后得到框
2. Bag of freebies
- IoU:
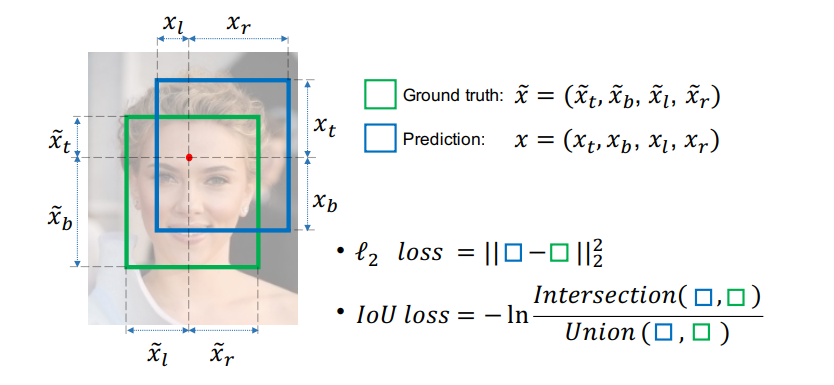
- GIoU: 本文中定义的 , , 的公式如下图所示, 表示的是能包含 和 的最小面积。

- DIoU/CIoU: DIou考虑了框之间的中心距离,即 ,其中 为预测框和真实框的中心点。CIoU在DIoU的基础上考虑了框的宽高,即 ,其中 , 。