从零入门深度学习(准备深入研究的)
Author:baiyucraft
BLog: baiyucraft’s Home
!!如果只是想用传统基于CNN的目标检测模型、语义分割模型删减几个模块来发论文的没必要入坑,因为目前来说这种论文已经趋于饱和,不太好发论文毕业。
!!建议打算深入学习模型原理的入坑,然后结合实验室已有的数据或资源来思考相关应用,简而言之理解计算机那边的前沿研究,然后应用在实验室已有资源上
!!学习方式主要基于 《动手学深度学习》 加上 读论文 以及 相关代码阅读复现,要想理解透彻,只能去读代码意思,解决复现bug
一、前置学习
- 懂得编程的逻辑(不论语言)
- python的数据类型,运算符,基本语法,pip包管理,类的基础概念(面向对象编程)
- 下述专业论文指的是发表在一些计算机类刊物会议上的,代表这个领域研究前沿的论文,这些论文可以学习最新的知识
- 下述应用论文指的是将视觉模型应用到具体领域的论文,有具体的对象以及实验方案,这些论文可以提供灵感以及一些实验方案
二、基础
1.一些概念(补充ing)
- 深度学习属于机器学习一种,机器学习是实现人工智能的一种方法
- 深度学习分CV(计算机视觉)和NLP(自然语言处理)
- 机器学习处理数据的模式是:收集数据,数据预处理,模型训练,验证模型
2.一些网站(更新ing)
- Kaggle 和 GitHub 等这种就不提了
- arxiv:是世界上最大的预印本网站,计算机专业论文基本在这上面都有
- Papers With Code:最好用的机器学习论文收录网站,能查到最新计算机专业领域的相关论文,以及一些视觉领域比较出名的排行榜,同时在排行榜上的一些SOTA模型。具体可以自己发掘
- Stork:SCI依据关键词论文推送,但是也有一些局限,基本也就是了解一些应用论文,
frontiers in plant science这个期刊的论文还是能收到的
3.学习部分
- 有微积分、线性代数基础知识,知道简单的公式运算(有助于理解张量),概率论普通了解即可
- 独立安装并使用pytorch环境,conda环境管理
- 《动手学深度学习》 序言-4.10,结合B站中的对应视频00-18,建议可以对着敲代码自己复现一遍相关代码。
- 通过上述学习明白感知机、多层感知机、多层感知机中的前向传播和反向传播,反向传播可以试着用numpy写写线性(全连接)反向传播的实现模式(结合算法设计与分析课)
三、入门
1. 图像分类的学习
- 《动手学深度学习》 5.1-7.7,B站视频的19-40
- 明白图像分类任务的目的,了解卷积神经的发展,自己复现以下网络的代码实现,并简要阅读对应论文:LeNet、AlexNet、VGG、NiN、GoogLeNet、Inception系列(V2、V3、V4)、ResNet、DenseNet、ResNeXt、MobileNet
- 阅读并了解一些论文:MobileNet后续系列(V2、V3、MNasNet)、SqueezeNet、ShuffleNet(V2)等。这些论文基本靠Nas搜索的超参数,所以不做要求
2.目标检测的学习
- 《动手学深度学习》 13.1-13.8,B站视频的41-45
- 理解目标检测任务的实际目标,理解目标检测模型中的输入、主干、颈部、检测头的构成,基本如下图所示:
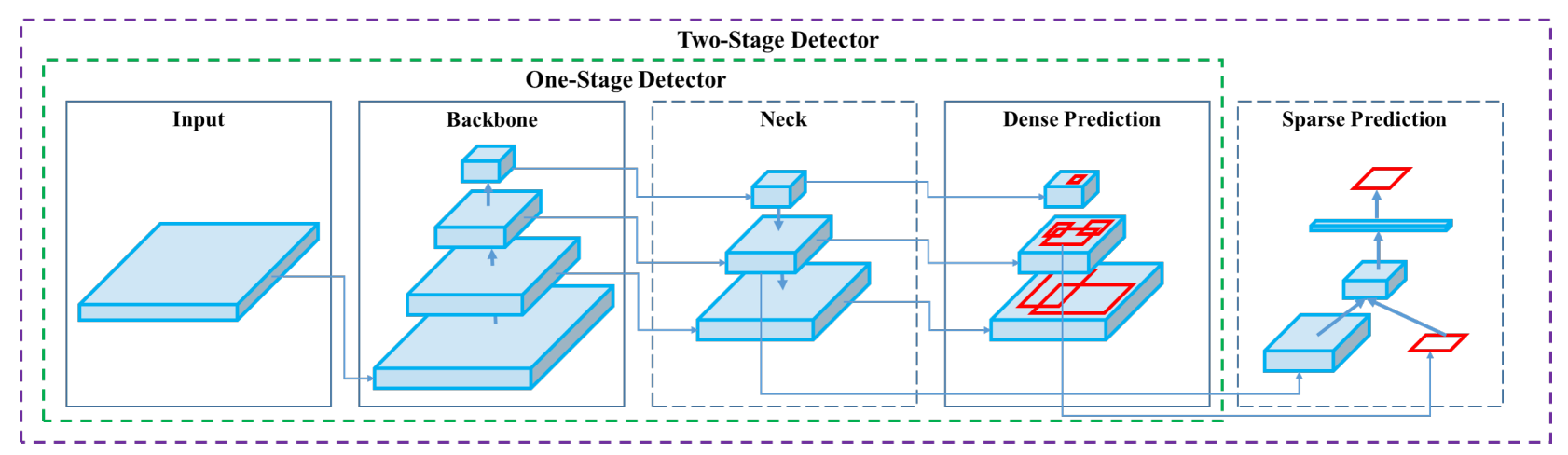
- 深入学习一下目标检测框架的原理:SSD、RCNN系列(Faster R-CNN)、YOLO系列( v3)等论文
- 可以结合网上的文章并精读相关代码:Faster R-CNN、SSD、YOLOv5等,这三种最经典的模型代码必须精读,一步步调试,理解每个模块干了什么,基本上读懂了这三份代码后,之后的代码阅读以及写起来会非常流畅
- 进一步的,经典的目标检测论文阅读,如RetinaNet(Focal Loss)、CornerNet等,论文是需要自己根据一些文章或者渠道去发掘的,特别是一些经典的论文,具体的可以自己从一些了解其创新点,与其他论文中不同的地方
- 具体的可以看(梳理中)YOLO 总结:从 YOLO 看目标检测 Object Detection(闲职了半年没写完的)
3.语义分割的学习
- 《动手学深度学习》 13.9-13.11,B站视频的46-48
- 理解语义分割、实例分割的实际目标,结合目标检测理解分割模型中的分割头,通过对目标检测以及语义分割、实例分割的学习明白视觉任务的下游任务的概念,实际上视觉任务本质上是通过一个分类模型作为图像的特征提取器,然后根据不同的下游任务目标(如检测、分割、深度估计等)来设计模型的输出
- 阅读经典分割模型的论文,如FCN、U-Net、PSPNet、DeepLab系列(v1、v2、v3、v3+)等,具体的其他经典论文自己发掘寻找,可能看着这篇论文的一些博客讲解中间就会提到其他论文,可以顺便看看创新点
- 精读两三份经典的分割模型代码:FCN(Pytorch自带库里有)、U-Net、DeepLabv3+等
4.注意力机制的学习
- 注意力机制其实算是一个通用视觉研究领域的子领域,目前注意力机制可以说是各家纷说。可能一种注意力机制效果好,另一种不好,但是两种结合效果比一种好。或者是同一种注意力机制在这个模型上效果好,在另一个模型上没效果甚至负面提升。所以以这种拼接形式发论文已经不太好发了!
- 阅读经典的一些注意力机制的论文并查看代码,如BAM、CBAM等
- 涉及Transformer的自注意力self-attention可以之后阅读
四、进阶
- 上述属于整个计算机视觉深度学习方面的初步学习,有了这些基础,看模型代码以及对视觉任务的理解能力会有个质的提升,后面就是该从阅读的论文中思考改应用在什么上面,有什么改进
1.主干模型进阶
- 目前在计算机视觉领域最火的模型结构是Transformer模型,但是在应用层面的出现还不算多,所以发论文的时候跟这个结合是很有利的创新点。
- Transformer的结构学习比较难,因为是从自然语言处理那边照搬过来的模型,模型中没有CNN这么形象的卷积滑动,都是一些向量的计算。
2.简单任务进阶
- 目标检测可以考虑小目标检测的研究(在图像输入前加GAN、在检测头上生成不拘泥与矩形框的输出等)
- 在多光谱图像应用中,实际上就是输入由3通道变成6通道,抑或是通过其他如植被指数的减少通道或增加通过
- 上述思路都可以多阅读视觉专业论文中寻找灵感,当然这些论文可能没经典的论文出名,所以可以略读
3.下游任务进阶
- 下游任务不止检测分割,还有目标跟踪、深度估计、视频理解、文字识别、关键点识别等,根据不同的输入和期望的输出都可以是一个视觉的任务
- 输入也可以是不止是图像,还可以是和文本结合,和雷达探测图结合,或者输出文本,这个就倾向于多模态领域的研究,当然涉及到文本就需要一些NLP的知识,这也是为什么Transformer为什么兴起的原因之一,可以很好的将CV与NLP的输入输出统一
从零入门深度学习(准备深入研究的)
http://baiyucraft.top/DeepLearning/DeepLearning-0.html