Author:baiyucraft
BLog: baiyucraft’s Home
原文:《动手学深度学习》
在机器学习中的大部分任务通常都是与预测有关的,当我们想预测一个数值时,就会涉及到回归问题。常见的例子有:预测价格(房屋、股票等)、预测住院时间(针对住院病人)、预测需求(零售销量)等。
一、线性回归的基本元素 线性回归linear regression是回归的各种标准工具中最简单而且最流行的。线性回归基于几个简单的假设:首先,假设自变量 x \boldsymbol x x x \boldsymbol x x
这里举一个实际例子,我们希望根据房子的面积area和房龄age来估算房屋价格price。在这个过程中我们需要一个真实的数据集,这个数据集包括了房屋的销售价格、面积和房龄,在机器学习是术语中叫做训练集training set,每行数据称为样本sample,也可以称为数据点data point或数据样本data instance。我们要试图预测的目标(在这个例子中是房屋价格)称为标签label或目标target。预测所依据的自变量(面积和房龄)称为特征features或协变量covariates。
通常,我们使用 n n n i i i x ( i ) = [ x 1 ( i ) , x 2 ( i ) ] T x^{(i)} = \left[x_1^{(i)}, x_2^{(i)}\right]^\mathrm{T} x ( i ) = [ x 1 ( i ) , x 2 ( i ) ] T y ( i ) y^{(i)} y ( i )
1.线性模型 我们需要先对该模型进行假设,即目标(房屋价格)可以表示特征(面积、房龄)的加权和,即:
p r i c e = w a r e a ⋅ a r e a + w a g e ⋅ a g e + b price = w_{area} · area + w_{age} · age + b p r i ce = w a re a ⋅ a re a + w a g e ⋅ a g e + b
其中 w a r e a w_{area} w a re a w a g e w_{age} w a g e weight,b b b bias,或称为偏移量offset、截距intercept。
权重weight决定了每个特征对我们预测值的影响。偏置bias是指当所有特征都取值为0时,预测值应该为多少。即使现实中不会有任何房子的面积是0或房龄正好是0年,我们仍然需要偏置项。如果没有偏置项,我们模型的表达能力将受到限制。 严格来说,上述式子是输入特征的一个仿射变换affine transformation。仿射变换的特点是通过加权和对特征进行线性变换linear transformation,并通过偏置项来进行平移translation。
同理类推,当我们的输入包含 d d d y ^ \widehat y y
y ^ = w 1 x 1 + ⋯ + w d x d + b \widehat y = w_1x_1 + \cdots + w_dx_d + b y = w 1 x 1 + ⋯ + w d x d + b
将所有特征放到 x ∈ R d \boldsymbol x \in \mathbb{R}^{d} x ∈ R d w ∈ R d \boldsymbol w \in \mathbb{R}^{d} w ∈ R d
y ^ = w T x + b \widehat{y} = \boldsymbol w^\mathrm{T} \boldsymbol x + b y = w T x + b
向量 x \boldsymbol x x x ∈ R n × d \boldsymbol x \in \mathbb{R}^{n \times d} x ∈ R n × d n n n X \boldsymbol X X X \boldsymbol X X y ^ ∈ R n \widehat y \in \mathbb{R}^{n} y ∈ R n
y ^ = X w + b \widehat y = \boldsymbol X \boldsymbol w + b y = X w + b
具体过程是给定训练数据特征 X \boldsymbol X X y y y w \boldsymbol w w b b b X \boldsymbol X X w \boldsymbol w w b b b y ^ \widehat y y y y y
在我们开始寻找最好的模型参数model parameters的w \boldsymbol w w b b b
一种模型质量的度量方式; 一种能够更新模型以提高模型预测质量的方法。 2.损失函数 回归问题中最常用的损失函数是平方误差函数。当样本 i i i y ^ ( i ) \widehat{y}^{(i)} y ( i ) y ( i ) y ^{(i)} y ( i )
l ( i ) ( w , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 l^{(i)}(\boldsymbol{w}, b) = \dfrac{1}{2} \left(\widehat{y}^{(i)} - y^{(i)}\right)^{2} l ( i ) ( w , b ) = 2 1 ( y ( i ) − y ( i ) ) 2
常数 1 2 \dfrac{1}{2} 2 1 1 1 1
由于平方误差函数中的二次方项,估计值 y ^ ( i ) \widehat{y}^{(i)} y ( i ) y ( i ) y ^{(i)} y ( i ) l l l n n n
L ( w , b ) = 1 n ∑ i = 1 n l ( i ) ( w , b ) = 1 2 1 n ∑ i = 1 n ( y ^ ( i ) − y ( i ) ) 2 = 1 2 n ∑ i = 1 n ( w T x ( i ) + b − y ( i ) ) 2 = 1 2 n ∥ X w + b − y ∥ 2 L(\boldsymbol{w}, b) = \dfrac{1}{n} \sum_{i=1}^{n} l^{(i)}(\boldsymbol{w}, b) = \dfrac{1}{2} \dfrac{1}{n} \sum_{i=1}^{n} \left(\widehat{y}^{(i)} - y^{(i)}\right)^{2} \\ \\ = \dfrac{1}{2n} \sum_{i=1}^{n}\left(\boldsymbol w^\mathrm{T} \boldsymbol x^{(i)} + b - y^{(i)}\right)^{2} = \dfrac{1}{2n} \left\|\boldsymbol{Xw} + b - \boldsymbol{y}\right\|^{2} L ( w , b ) = n 1 i = 1 ∑ n l ( i ) ( w , b ) = 2 1 n 1 i = 1 ∑ n ( y ( i ) − y ( i ) ) 2 = 2 n 1 i = 1 ∑ n ( w T x ( i ) + b − y ( i ) ) 2 = 2 n 1 ∥ Xw + b − y ∥ 2
在训练模型时,我们希望寻找一组参数 ( w ∗ , b ∗ ) \left(\boldsymbol{w}^*, b^*\right) ( w ∗ , b ∗ )
w ∗ , b ∗ = a r g m i n w , b L ( w , b ) \boldsymbol{w}^*, b^* = \mathop{argmin}\limits_{\boldsymbol{w}, b} L(\boldsymbol{w}, b) w ∗ , b ∗ = w , b a r g min L ( w , b )
3.解析解 线性回归是一个很简单的优化问题,而线性回归的解可以用一个公式简单地表达出来,也就是其有显式解,这类解叫做解析解analytical solution。
针对 X w + b \boldsymbol {Xw} + b Xw + b X \boldsymbol{X} X X \boldsymbol{X} X X ← [ X , 1 ] \boldsymbol{X} \gets [\boldsymbol{X}, 1] X ← [ X , 1 ] w \boldsymbol w w b b b w \boldsymbol w w w ← [ w b ] \boldsymbol{w} \gets \begin{bmatrix} \boldsymbol{w} \\ b \end{bmatrix} w ← [ w b ] L ( w , b ) = 1 2 n ∥ X w + b − y ∥ 2 = 1 2 n ∥ X w − y ∥ 2 L(\boldsymbol{w}, b) = \dfrac{1}{2n} \left\|\boldsymbol{Xw} + b - \boldsymbol{y}\right\|^2 = \dfrac{1}{2n} \left\|\boldsymbol{Xw} - \boldsymbol{y}\right\|^{2} L ( w , b ) = 2 n 1 ∥ Xw + b − y ∥ 2 = 2 n 1 ∥ Xw − y ∥ 2
我们将损失函数 L ( w , b ) L(\boldsymbol w, b) L ( w , b ) w \boldsymbol w w
∂ L ( w , b ) ∂ w = 1 n ( X w − y ) T X = 0 ⇔ X T w T X = y T X ⇔ X T w X = X T y ⇔ w = ( X T ) − 1 X T y ( X ) − 1 = ( X T X ) − 1 X T y \dfrac{\partial{L(\boldsymbol{w}, b)}}{\partial{\boldsymbol w}} = \dfrac{1}{n}(\boldsymbol{Xw} - \boldsymbol{y})^\mathrm{T}\boldsymbol{X} = 0 \\ \Leftrightarrow \boldsymbol{X}^\mathrm{T} \boldsymbol{w}^\mathrm{T} \boldsymbol{X} = \boldsymbol{y}^\mathrm{T} \boldsymbol{X} \\ \Leftrightarrow \boldsymbol{X}^\mathrm{T} \boldsymbol{w} \boldsymbol{X} = \boldsymbol{X}^\mathrm{T} \boldsymbol{y} \\ \Leftrightarrow \boldsymbol{w} = \left(\boldsymbol{X}^\mathrm{T}\right)^\mathrm{-1} \boldsymbol{X}^\mathrm{T} \boldsymbol{y} \left(\boldsymbol{X}\right)^\mathrm{-1} = \left(\boldsymbol{X}^\mathrm{T} \boldsymbol{X}\right)^\mathrm{-1} \boldsymbol{X}^\mathrm{T} \boldsymbol{y} ∂ w ∂ L ( w , b ) = n 1 ( Xw − y ) T X = 0 ⇔ X T w T X = y T X ⇔ X T w X = X T y ⇔ w = ( X T ) − 1 X T y ( X ) − 1 = ( X T X ) − 1 X T y
4.小批量随机梯度下降 除了线性回归这样简单的模型外,其他模型大部分是得不到解析解的,而且在很多时候,那些难以得到解析解的模型效果更好,因此,弄清楚如何训练这些难以优化的模型是非常重要的。
这里采用的是梯度下降gradient descent的方法,这种方法几乎可以优化所有深度学习模型。它通过不断地在损失函数递减的方向上更新参数来降低误差。
梯度下降最简单的用法是计算损失函数(即数据集中所有样本的损失均值)关于模型参数的导数(在这里也可以称为梯度)。但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本,这种变体就叫做小批量随机梯度下降minibatch stochastic gradient descent。
在每次迭代中,我们首先随机抽样一个小批量 B \mathcal B B η \eta η w 0 \boldsymbol{w_0} w 0 b 0 b_0 b 0
对于平方损失和仿射变换,我们可以明确地写成如下形式:
w t ← w t − 1 − η ∣ B ∣ ∑ i ∈ B ∂ ∂ w t − 1 l ( i ) ( w t − 1 , b ) = w t − 1 − η ∣ B ∣ ∑ i ∈ B ∂ ∂ w t − 1 1 2 ( w t − 1 T x ( i ) + b − y ( i ) ) 2 = w t − 1 − η ∣ B ∣ ∑ i ∈ B x ( i ) ( w t − 1 T x ( i ) + b − y ( i ) ) \boldsymbol{w_t} \gets \boldsymbol{w_{t-1}} - \dfrac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}\dfrac{\partial}{\partial \boldsymbol{w_{t-1}}} l^{(i)}(\boldsymbol{w_{t-1}}, b) \\ = \boldsymbol{w_{t-1}} - \dfrac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}\dfrac{\partial}{\partial \boldsymbol{w_{t-1}}} \dfrac{1}{2} \left(\boldsymbol w_{t-1}^\mathrm{T} \boldsymbol x^{(i)} + b - y^{(i)}\right)^{2} \\ = \boldsymbol{w_{t-1}} - \dfrac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \boldsymbol{x^{(i)}} \left(\boldsymbol w_{t-1}^\mathrm{T} \boldsymbol x^{(i)} + b - y^{(i)}\right) w t ← w t − 1 − ∣ B ∣ η i ∈ B ∑ ∂ w t − 1 ∂ l ( i ) ( w t − 1 , b ) = w t − 1 − ∣ B ∣ η i ∈ B ∑ ∂ w t − 1 ∂ 2 1 ( w t − 1 T x ( i ) + b − y ( i ) ) 2 = w t − 1 − ∣ B ∣ η i ∈ B ∑ x ( i ) ( w t − 1 T x ( i ) + b − y ( i ) )
b ← b t − 1 − η ∣ B ∣ ∑ i ∈ B ∂ ∂ b t − 1 l ( i ) ( w , b t − 1 ) = b t − 1 − η ∣ B ∣ ∑ i ∈ B ∂ ∂ b t − 1 1 2 ( w T x ( i ) + b t − 1 − y ( i ) ) 2 = b t − 1 − η ∣ B ∣ ∑ i ∈ B ( w T x ( i ) + b t − 1 − y ( i ) ) b \gets b_{t-1} - \dfrac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \dfrac{\partial}{\partial b_{t-1}} l^{(i)}(\boldsymbol{w}, b_{t-1}) \\ = b_{t-1} - \dfrac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \dfrac{\partial}{\partial b_{t-1}} \dfrac{1}{2} \left(\boldsymbol w^\mathrm{T} \boldsymbol x^{(i)} + b_{t-1} - y^{(i)}\right)^{2} \\ = b_{t-1} - \dfrac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \left(\boldsymbol{w}^\mathrm{T} \boldsymbol x^{(i)} + b_{t-1} - y^{(i)}\right) b ← b t − 1 − ∣ B ∣ η i ∈ B ∑ ∂ b t − 1 ∂ l ( i ) ( w , b t − 1 ) = b t − 1 − ∣ B ∣ η i ∈ B ∑ ∂ b t − 1 ∂ 2 1 ( w T x ( i ) + b t − 1 − y ( i ) ) 2 = b t − 1 − ∣ B ∣ η i ∈ B ∑ ( w T x ( i ) + b t − 1 − y ( i ) )
公式中的 w \boldsymbol{w} w x \boldsymbol{x} x ∣ B ∣ |\mathcal{B}| ∣ B ∣ batch size),η \eta η learning rate。
调参hyperparameter tuning是选择超参数的过程。超参数通常是我们根据训练迭代结果来调整的,而训练迭代结果是在独立的验证数据集validation dataset上评估得到的。
在训练了预先确定的若干迭代次数后(或者直到满足某些其他停止条件后),我们记录下模型参数的估计值,表示为 w ^ \widehat{\boldsymbol w} w b ^ \widehat{b} b
线性回归恰好是一个在整个域中只有一个最小值的学习问题。但是对于像深度神经网络这样复杂的模型来说,损失平面上通常包含多个最小值。幸运的是,出于某种原因,深度学习实践者很少会去花费大力气寻找这样一组参数,使得在训练集上的损失达到最小。事实上,更难做到的是找到一组参数,这组参数能够在我们从未见过的数据上实现较低的损失,这一挑战被称为泛化generalization。
给定学习到的线性回归模型 w ^ T x + b ^ \widehat{\boldsymbol w}^\mathrm{T} \boldsymbol x + \widehat{b} w T x + b x 1 x_1 x 1 x 2 x_2 x 2 prediction或推断inference。
二、矢量化加速 在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。为了实现这一点,需要我们对计算进行矢量化,从而利用线性代数库,而不是在Python中编写开销高昂的for循环。
由于在沐神的书中将频繁地进行运行时间的基准测试,所以定义一个计时器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import timeimport numpy as npclass Timer :"""记录多次运行时间。""" def __init__ (self ):def start (self ):"""启动计时器。""" def stop (self ):"""停止计时器并将时间记录在列表中。""" return self.times[-1 ]def avg (self ):"""返回平均时间。""" return sum (self.times) / len (self.times)def sum (self ):"""返回时间总和。""" return sum (self.times)def cumsum (self ):"""返回累计时间。""" return np.array(self.times).cumsum().tolist()
下面对两个全1的1000维向量,分别用for遍历的方法和使用重载的 + 运算符来计算按元素的和。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 n = 10000 for i in range (n):print (f'{timer.stop():.5 f} sec' )print (f'{timer.stop():.5 f} sec' )
运行结果:
可以看到速度天壤之别。
三、正态分布与平方损失 接下来,我们通过对噪声分布的假设来解读平方损失目标函数。
正态分布normal distribution和线性回归之间的关系很密切,学过概率的都知道,若随机变量 x x x μ \mu μ σ 2 \sigma^{2} σ 2 σ \sigma σ
p ( x ) = 1 2 π σ 2 e x p ( − 1 2 σ 2 ( x − μ ) 2 ) p(x) = \dfrac{1}{\sqrt{2 \pi \sigma^{2}}}exp\left(-\dfrac{1}{2\sigma^{2}} (x-\mu)^{2}\right) p ( x ) = 2 π σ 2 1 e x p ( − 2 σ 2 1 ( x − μ ) 2 )
下面在python中定义一个计算正态分布的函数
1 2 3 def normal(x, mu, sigma):
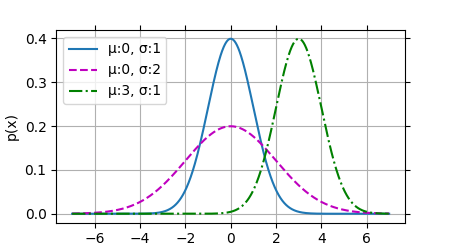
然后可视化正态分布:
1 2 3 4 5 6 7 7 , 7 , 0.01 )0 , 1 ), (0 , 2 ), (3 , 1 )]for mu, sigma in params], xlabel='x' , ylabel='p(x)' , figsize=(4.5 , 2.5 ),f'{chr (956 )} :{mu} , {chr (963 )} :{sigma} ' for mu, sigma in params])
运行结果:
就像我们所看到的,改变均值会产生沿 x x x
均方误差损失函数(简称均方损失)可以用于线性回归的一个原因是:我们假设了观测中包含噪声,其中噪声服从正态分布。噪声正态分布如下式:
y = w T x + b + ϵ w h e r e ϵ ∼ N ( 0 , σ 2 ) y = \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x} + b + \epsilon \quad where \quad \epsilon \sim \mathcal{N}\left(0,\sigma^{2}\right) y = w T x + b + ϵ w h ere ϵ ∼ N ( 0 , σ 2 )
因此,我们现在可以写出通过给定的 x \boldsymbol{x} x y y y likelihood:
P ( y ∣ x ) = 1 2 π σ 2 e x p ( − 1 2 σ 2 ( y − w T x − b ) 2 ) P(y|\boldsymbol{x}) = \dfrac{1}{\sqrt{2 \pi \sigma^{2}}}exp\left(-\dfrac{1}{2\sigma^{2}} \left(y - \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x} -b\right)^{2}\right) P ( y ∣ x ) = 2 π σ 2 1 e x p ( − 2 σ 2 1 ( y − w T x − b ) 2 )
现在,根据最大似然估计法,参数 w \boldsymbol w w b b b
P ( y ∣ X ) = ∏ i = 1 n P ( y ( i ) ∣ x ( i ) ) P(\boldsymbol{y}|\boldsymbol{X}) = \prod_{i=1}^{n} P\left(y^{(i)}|\boldsymbol{x}^{(i)}\right) P ( y ∣ X ) = i = 1 ∏ n P ( y ( i ) ∣ x ( i ) )
根据最大似然估计法选择的估计量称为最大似然估计量。 虽然使许多指数函数的乘积最大化看起来很困难,但是我们可以在不改变目标的前提下,通过最大化似然对数来简化。 由于历史原因,优化通常是说最小化而不是最大化。我们可以改为最小化负对数似然 − ln P ( y ∣ X ) −\ln P(\boldsymbol{y}|\boldsymbol{X}) − ln P ( y ∣ X )
− ln P ( y ∣ X ) = − ln ( 1 2 π σ 2 e x p ( − 1 2 σ 2 ( y ( i ) − w T x ( i ) − b ) 2 ) ) = ∑ i = 1 n 1 2 ln ( 2 π σ 2 ) + 1 2 σ 2 ( y ( i ) − w T x ( i ) − b ) 2 −\ln P(\boldsymbol{y}|\boldsymbol{X}) = −\ln \left(\dfrac{1}{\sqrt{2 \pi \sigma^{2}}}exp\left(-\dfrac{1}{2\sigma^{2}} \left(y^{(i)} - \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(i)} -b\right)^{2}\right) \right) \\ = \sum_{i=1}^{n} \dfrac{1}{2} \ln\left(2\pi\sigma^{2}\right) + \dfrac{1}{2\sigma^{2}} \left(y^{(i)} - \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(i)} -b\right)^{2} − ln P ( y ∣ X ) = − ln ( 2 π σ 2 1 e x p ( − 2 σ 2 1 ( y ( i ) − w T x ( i ) − b ) 2 ) ) = i = 1 ∑ n 2 1 ln ( 2 π σ 2 ) + 2 σ 2 1 ( y ( i ) − w T x ( i ) − b ) 2
现在我们只需要假设 σ \sigma σ w \boldsymbol{w} w b b b 1 2 σ 2 \frac{1}{2\sigma^{2}} 2 σ 2 1 σ \sigma σ
四、从线性回归到深度网络 我们可以将线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。